DataLearner to łatwe w użyciu narzędzie do wykrywania kopalni i odkrywania wiedzy z własnych kompatybilnych arbowych i formatowanych CSV. Jest w pełni samodzielny, nie wymaga żadnych zewnętrznych pamięci masowej ani łączności sieciowej - buduje modele bezpośrednio na telefonie lub tablecie.
>> ARFF i CSV Support
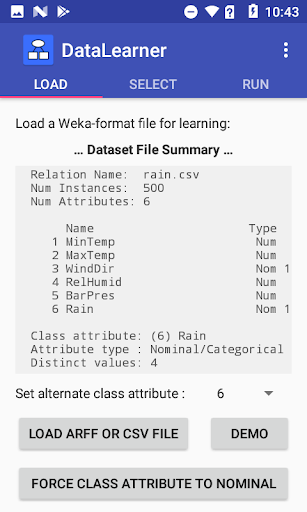
Zestawy danych Treningowy muszą być albo CSV (zmienna przecinkowa) lub format WEKA ARFF.
Pliki CSV muszą mieć następujące funkcje:
* Uwzględnij wiersz nagłówek
* Atrybut klasy jest początkowo ustawiony jako ostatnia kolumna
>> Atrybut grupy Force do nominalnego
Najbardziej algorytmów DataLearner spodziewa się nominalnych / kategorycznych atrybutów klasy i przy użyciu atrybutu klasy numerycznej spowoduje awarię algorytmów. Nowa "atrybut klasy Force do nominalnej" jest to nominalne ", jednak atrybuty klasy nominalnej z zbyt wieloma różnymi wartościami mogą wykorzystywać za dużo pamięci RAM.
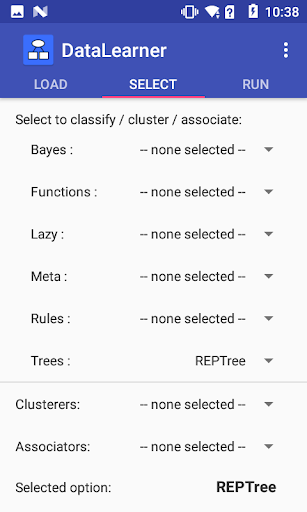
DataLearner Cechy klasyfikacja, stowarzyszenie i klastrowanie algorytmy z otwartego źródła WEKA (Środowisko Waikato do analizy wiedzy) Pakiet, a także nowe algorytmy opracowane przez jednostkę badawczą Nauki Data (DSRU) w Karola Sturt University. W połączeniu aplikacja zapewnia 42 algorytmy maszynowo-hullingowe / wydobywcze, w tym losowy, C4.5 (J48) i NaiveBayes.
DataLearner zbiera informacje - Wymaga dostępu do przechowywania urządzenia, aby załadować zbiory danych i zbudować modele uczenia maszynowego.
* DataLearner jest używany jako narzędzie do nauczania w
ITC573 Dane i wiedza Temat inżynierii
dla Master of Information Technology Stopień podyplomowego na Uniwersytecie Karola Strurt.
* Badania DataLearner zostały zaprezentowane w ADMA 2019 (15. Międzynarodowa konferencja na temat zaawansowanych wydobywczych danych i aplikacji) i opublikowane w "Wykłady" Sztuczna inteligencja "(Springer)
Pobierz zasoby:
GPL3-licencjonowany kod źródłowy na Github:
https://github.com/darrenyatesau/datalearner
Szybki wideo na YouTube:
https://youto.be/h-7petjzf-g
Papier badawczy na Arxiv:
https://arxiv.org/abs/1906.03773
AUSDM 2018 Papier konferencyjny, który zainicjował DataLearner:
https: //www.researchgate.net/Publication/331126867
Naukowcy, jeśli korzystasz z tej aplikacji w aplikacjach badawczych, proszę przytoczyć artykuły badawcze powyżej. Dzięki.
Algorytmy uczenia maszynowego obejmują:
• Bayes - Bayesnet, NaiveBayes
• Funkcje - logistyczne, proste, multilayerperceptron (sieć neuronowa)
• Lazy - IBK (K najbliższy sąsiedzi) , Kstar
• Meta - adaboostm1, pakiet, logitboost, Multiboostab, Losowy Komitet, Randomsubspace, RotationForest
Reguły - Reguła koniunkcyjna, Tabela decyzyjna, DTNB, JRIP, Otener, Część, Ridor, Zeror
• Drzewa - Adtree, BFTree, Dectorstump, Forestpa, J48 (C4.5), Landtree, Losowy las, Randomtree, Reptree, SimpleCart, Spaarc, Sysfor.
• Kastery - DBSCAN, Oczekiwania Maksymalizacja (EM), najdalsze, FilterCierser , SimpleKMeans
• Stowarzyszenia - Apriori, Filteredassociator, FPGrowth
Zastrzeżenie: To oprogramowanie jest dostarczane "AS-IS" - podczas gdy został przetestowany, żadna gwarancja lub gwarancja jest dorozumiana. Użyj go na własnym ryzyku. Twoje pobieranie tego oprogramowania pokazuje, że zgadzasz się na te warunki.
v1.1.7
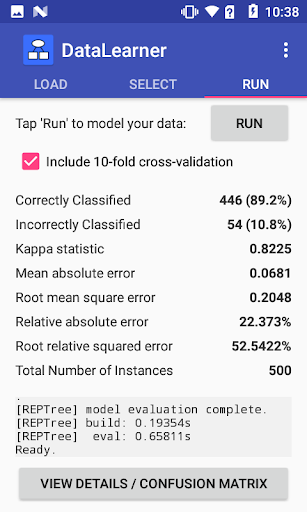
* Enabled View Details/Confusion Matrix button after no-CV model build only.
v1.1.6
* Enabled all trees in Random Forest to appear in Confusion Matrix/Model output.
* Added copy-paste to clipboard of Confusion Matrix/Model output.
v1.1.5
* updated error message to suggest using 'Force class attribute to nominal' button on Load screen.
v1.1.4
*fixed introduced bug preventing some statistics from appearing with numeric-class datasets.




9Apps 4.9